

树状数组,也称二叉索引树(Binary Index Tree, BIT),是很多OIer心中最简洁优美的数据结构之一
最简单的树状数组支持两种操作,时间复杂度均为 $O(logn)$:
- 单点修改:更改数组中一个元素的值
- 区间查询:查询一个区间内所有元素的和
引入
回顾一下,我们说,我们要实现两种操作:单点修改和区间求和。对于普通数组而言,单点修改的时间复杂度是 $O(1)$ ,但区间求和的时间复杂度是 $O(n)$

当然,我们也可以用前缀和的方式去维护这个数组,这样的话区间求和的时间复杂度降到了 $O(1)$,但单点修改会影响到后面的所有元素,时间复杂度上升到了 $O(n)$
程序最后跑多长时间,是由最慢的一环决定的,我们希望找到一种折中的方法,使得无论是单点查询还是区间求和,它都能不那么慢的完成
注意到我们对 $[a, b]$ 进行区间查询只需查询 $[1, b]$ 和 $[1, a)$ 然后相减即可(具体可看前缀和),所以我们可以把区间查询问题转化为求前$n$项和的问题
关于数组的维护,有个很自然的想法:可以用一个数组 C 维护若干个小区间,单点修改时,只更新包含这一元素的区间;求前n项和时,通过将区间进行组合,得到从 1 到 n 的区间,然后对所有用到的区间求和。实际上,设原数组是 $A$,如果 $C_{i}$ 维护的区间是 $[A_{i},A_{i}]$,此结构就相当于普通数组(还浪费了一倍内存);如果 $C_{i}$ 维护的区间是 $[1,A_{i}]$,此结构就相当于前缀和。
树状数组很好的平衡了两种操作的时间复杂度:单点修改和区间求和
树状数组
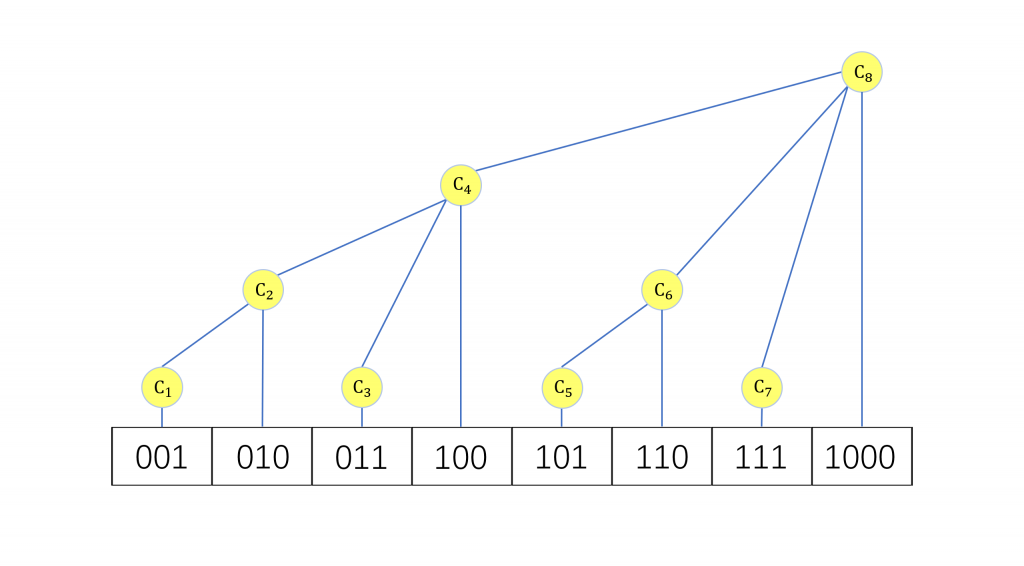
树状数组巧妙的利用了二进制(实际上,树状数组的英文名: Binary Index Tree,直译过来就是二进制下标树)。例如 11,转化为二进制就是 $(1011)_{2}$ ,如果我们要求前11项和,可以分别查询 $( (0000)_{2} , (1000)_{2} ]$ 、
$( (1000)_{2} , (1010)_{2} ]$ 以及 $( (1010)_{2} , (1011)_{2} ]$ 的和,也就是 $( 0, 8 ]、( 8, 10 ]、( 10, 11 ]$ 再相加。这三个区间其实就是不断去掉二进制数 11 最右边的一个 1 的过程(如下图)

让我们定义,二进制数最右边的一个 1,连带着它之后的 0 为 lowbit(Ai)。那么我们用 Ci 维护区间
$(A_{i} - lowbit_{i},A_{i}]$。显然,在这个情况下,查询前n项和时需要合并的区间数是少于 $log_{2}n$ 的
那么,在树状数组中,更新就像是一个向上爬的过程。一路向上更新,直到MAXN(树状数组的容量)
我们举个例子来看看这树是这么爬的。现有二进制数 $(100110)_{2}$ ,包含它的最小区间就是 $( (100100)_{2},(100110)_{2} ]$
然后,它肯定也位于区间$( (100000)_{2},(101000)_{2} ]$内。然后是$( (100000)_{2},(110000)_{2} ]$,最后是$( 0,(1000000)_{2} ]$

如上图,每一步都把从右边起一系列连续的1变为0,再把这一系列1的前一位0变为1。这看起来像是一个进位的过程对吧?实际上,每一次加的正是 lowbit(x)(lowbit(x)的值每次会是 x 的二进制最后一个 1 所在的位置对应的十进制的值,比如lowbit(5) = 1, lowbit(6) = 2 ( $5 = (101)_{2}\quad6 = (110)_{2}$ ) )
这样,我们更新的区间数不会超过 $log_{2}n$。一个能以 $O(log\ n)$ 时间复杂度进行单点修改和区间查询的数据结构就诞生了。
树状数组的实现
前面已经详细讲了树状数组的计算过程,实现倒是件简单的事情了。不过我们需要先解决一个重要的问题:lowbit() 函数怎么写?如果一位一位验证的话,会形成额外的时间开销。然而,我们有这样神奇的一个公式:
$$
lowbit(x)=x \ & \ (-x)
$$
为什么可以这样?我们需要知道,计算机里有符号数一般是以补码的形式存储的。$-x$相当于$x$按位取反再加1,会把结尾处原来1000…的形式,变成0111…,再变成1000…;而前面每一位都与原来相反。这时我们再把它和$x$按位与,得到的结果便是lowbit(x)。下面的图中举了两个例子:

现在我们可以愉快地实现树状数组了:
单点修改
int tree[MAXN];
inline void add(int i, int x)
{
for (int pos = i; pos < MAXN; pos += lowbit(pos))
tree[pos] += x;
}
求前n项和
inline int query(int n)
{
int ans = 0;
for (int pos = n; pos; pos -= lowbit(pos))
ans += tree[pos];
return ans;
}
区间查询
inline int query(int a, int b)
{
return query(b) - query(a - 1);
}
树状数组的应用
求逆序对
在数组中,存在 $i < j\ ,\ a[i] > a[j]$ 时,我们称 $(a[i],\ a[j])$ 为数组中的一对逆序对
求逆序对主要有两种方法,一种是归并排序,另一种就是我们这里介绍的树状数组求法
不过使用树状数组求逆序对时,数组中存在负数时,需要对数组进行一定的处理(毕竟下标没有负数)
流程
使用树状数组求逆序对其实很简单:
- 找出数组中 最大 的数 $maxn$,创建一个大小为 $maxn + 1$ 的树状数组
- 将数组中的数 顺序 加入树状数组中
- 在加入一个数时,计算树状数组中 大于 它的数的总数
- 将这个数加入树状数组中
从前文可以知道,树状数组的强项就是求前缀和。所以,我们使用 tree[i] 来记录数组中 $i$ 出现的次数,每当我们求一个数存在的逆序对的个数时,我们只需要求树状数组中比这个数大的区间内有多少个数即可(也就是 query(MAXN) - query(i - 1))
代码实现
const int MAXN = 7; // 偷懒提前定好了
int tree[MAXN];
inline int lowbit(int x)
{
return x & -x;
}
inline void add(int i, int x)
{
for (int pos = i; pos < MAXN; pos += lowbit(pos))
tree[pos] += x;
}
inline int query(int n) // 单点查询
{
int ans = 0;
for (int pos = n; pos; pos -= lowbit(pos))
ans += tree[pos];
return ans;
}
int main()
{
int arr[5] = {5, 6, 3, 1, 2};
int ans = 0, arrmax = 6; // 偷懒没写求数组最大值的代码
for (int i = 0; i < 5; ++i)
{
ans += query(arrmax) - query(arr[i] - 1); // 计算这个数的逆序对个数
add(arr[i], 1); // 将这个数添加进树状数组中
}
cout << ans << endl;
return 0;
}
最后输出结果为 $8$,读者可自行使用纸笔验算
由于下标 没有负数,所以这种方法只能用于数组中的数均为 正整数 的情况
优化
在上面版本中,我们每次计算都要进行两次 query() 的计算,有些浪费时间
我们只需要一个很小的改动就可以计算的次数减半,将之前的 顺序 改为 倒序
由于逆序对的数量其实是 数组中这个数的后面有多少个数是小于它的数。那么,我们 倒序 输入数组中的数,就只用进行一次 query() 计算了(因为只用计算一次前缀和即可)
对于空间来说,如果我们遇到类似 a[] = {1, 5, 3, 999} 这样的数组,如果开一个 $999$ 的数组就造成了大部分空间的浪费
对此我们可以使用 离散化 的手段,将原数组变为 {4, 2, 3, 1}(也就是第 $i$ 大的数在原数组中的位置,例子中原数组最大的数是 $999$,在第四位,所以新数组第一位为 $4$)
但是需要注意,离散化后所求的为新数组的 顺序对
